
Fin de "num=100" & son Effet Papillon
Google abandonne &num=100 : quelles conséquences pour le SEO et GEO ?

Salut, c’est Alexis 👋
Bienvenue à 348 (❤️🔥) nouveaux abonnés depuis la dernière édition ! Si vous n’êtes pas encore abonné, il n’y a rien de plus simple ⬇️
Cette édition de la newsletter aurait dû partir il y a plus d’une semaine, mais entre la famille, le travail et les engagements pris, je ne vous l’envoie qu’aujourd’hui 😉
Cet article contient beaucoup de visuels, si vous avez des difficultés de le visionner, rendez-vous sur la version web complète sur le lien :

SEO Summit 2025 au Parc des Princes !
Avant de se lancer dans le vif du sujet, la semaine prochaine c’est le SEO Summit 2025 au Parc des Princes !
J’y serai les 2 jours :
Lundi pour co-animer une master-classe “Maîtriser l’Optimisation on-site pour les Moteurs IA“.
Mardi pour une conférence “La face cachée des moteurs génératifs : SearchGPT, Perplexity AI, Claude AI“.
La billetterie ferme demain, ne tardez pas à réserver votre place, je vais être ravi de voir tout le monde !

Google met fin à l’option &num=100 dans ses résultats de recherche
Comme vous le savez, le 10 septembre, Google a discrètement désactivé dans ses paramètres de recherche l’option permettant d’afficher 100 résultats par page.
Un changement anodin, qui aurait pu passer inaperçu comme tant d’autres effectués par Google, a pourtant secoué de nombreux aspects de l’écosystème de la recherche.
Pour rappel, cette option ajoutait à l’URL des pages de résultats de recherche un petit paramètre &num=100, permettant d’obtenir, pour chaque requête, le TOP-100 des meilleurs résultats au lieu des 10 liens bleus habituels.
Pour moi, c’était très pratique pour avoir une vision d’ensemble des résultats liés à une requête.
Désormais, impossible d’avoir sur une seule page plus de 10 liens bleus.
Pour consulter davantage de résultats, il faut passer par la pagination, ce qui demande plus d’efforts, de temps et de coût s’il s’agit de la collecte automatisée.
Voyons ensemble ce qui a changé et comment vivre travailler maintenant avec 😉
Qui utilisait &num=100 ?
Avant de passer à l’analyse de l’impact de ce changement, essayons déjà de répondre à la question centrale : “Mais qui ont été ceux qui consultaient les résultats de Google par 100 ?”.
Car de la réponse à cette question dépendra la manière dont nous devrons interpréter les changements.
On peut distinguer 2 principaux groupes d’« utilisateurs » de cette option :
Les utilisateurs avancés (ceux qui connaissaient l’existence de l’option et l’activaient volontairement dans les réglages de Google pour avoir accès à un ensemble élargi de résultats pour chaque requête). Ce sont des personnes avec “une déformation professionnelle” comme nous, les consultants SEO, ou des gens tout à fait normaux qui sont dans la recherche immobilière, achat de voiture, études, travaux de recherche, etc.
Les nombreux outils de scraping des résultats de Google, qu’il s’agisse d’un usage interne (SEMRush, Seranking, Ahrefs etc.) ou de la revente de données (SERP API, ValueSerp, DataForSEO, etc.).
Même si Google ne partage pas les informations sur l’usage, je pense qu’on peut affirmer avec certitude que le premier groupe reste assez marginal par rapport à l’ensemble des utilisateurs de Google.
En revanche, le 2nd – celui des outils de scraping – représente une véritable industrie.
On oublie souvent que derrière des services comme Semrush, Ahrefs, ou Haloscan (pour la collecte de mots-clés), Sistrix (pour le suivi de la visibilité), Seranking (pour le suivi des positionnements) se cache une mécanique colossale : pour fonctionner, ces plateformes doivent recueillir des données de Google sur des centaines de millions de requêtes. Et faire ça en permanence.
Une industrie qui a encore changé d’échelle avec la nouvelle que OpenAI s’était mis à collaborer avec SERP API pour avoir accès aux données issues des résultats de recherche Google.
Tout ce contexte, pousse le moteur de recherche de Mountain View à faire un nouveau pas de son côté pour lutter contre les bots de scraping.
En début d’année, il a déjà imposé l’exécution du Javascript pour pouvoir consulter ses résultats, cette fois-ci il interdit de collecter 100 résultats à la fois (que les outils automatisés récupéraient par défaut).
Gardons tout cela en tête et passons maintenant aux impacts que ce changement a apportés.

Google Search Console
1. Impressions, clics, position et CTR moyen
Commençons par la Search Console.
Connectez-vous à votre compte et regardez ce qui se passe depuis le 10 septembre.
Vous allez certainement retrouver des tendances pareilles :
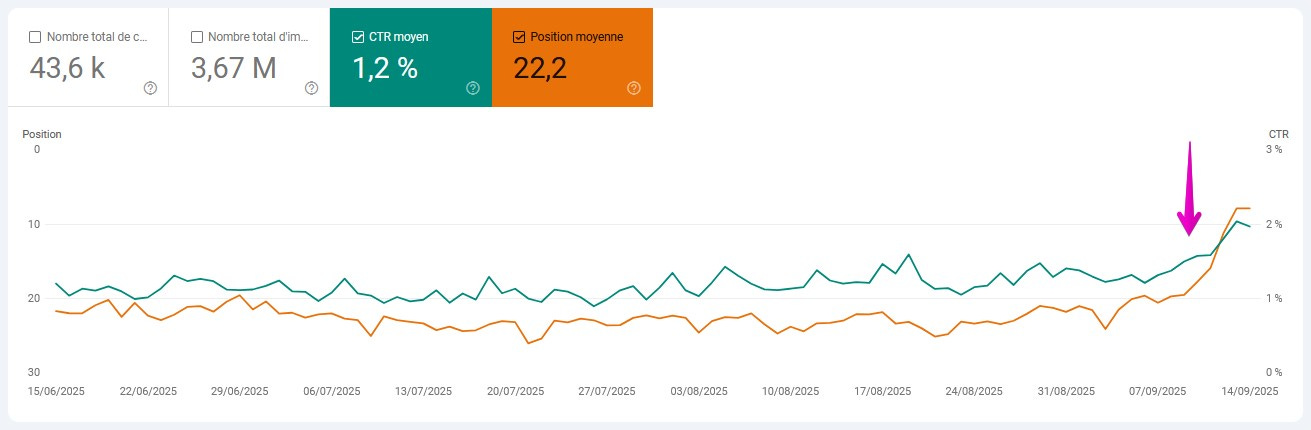
La position moyenne et le CTR s’envolent.
Les impressions chutent.
Les clics restent stables.
La position moyenne et le CTR s’envolent:
Pour comprendre ces fluctuations dans les indicateurs, il faut bien rappeler la manière dont ils sont calculés par la Search Console.
Tous les indicateurs de l’outil - clics, impressions, position et CTR moyen, sont rattachées aux requêtes de recherche.
Les requêtes de recherche apparaissent dans les rapports de la Search Console uniquement s’ils génèrent des impressions dans les résultats de Google.
Donc, s’il n’y a pas d’impressions, il n’y a pas de requêtes de recherche, ni d’indicateurs.
C’est pour cette raison, par exemple, que vous pouvez observer des fluctuations inhabituelles de la position moyenne le week-end :
Ce n’est pas parce que votre site se positionne moins bien (ou mieux) le samedi et le dimanche, mais simplement parce que le comportement des utilisateurs diffère. La palette de leurs requêtes change, et cela influe mécaniquement sur la position moyenne.
La position moyenne d’un site ou d’une page affichée dans la Search Console est fortement influencée par les requêtes situées en périphérie des résultats de recherche de Google, aux positions 80, 90 ou 100, qui la tirent vers le bas.
Avec une page de recherche affichant 100 résultats, ces requêtes généraient des impressions, donc apparaissaient dans les rapports de la Google Search Console et donc tiraient la position moyenne vers le bas.
Désormais, avec des pages limitées à 10 résultats par défaut, ces requêtes deviennent comme invisibles : pas d’impressions – pas de requête – pas de position.
Cet effet d’« ancre » qui faisait baisser artificiellement la position moyenne a disparu.
C’est globalement un point positif, car nous disposons désormais d’une position moyenne plus précise pour les requêtes qui se classent bien.
Chute des impressions :
Une autre chose qu’on observe est la chute subite des impressions à partir du 10 septembre :
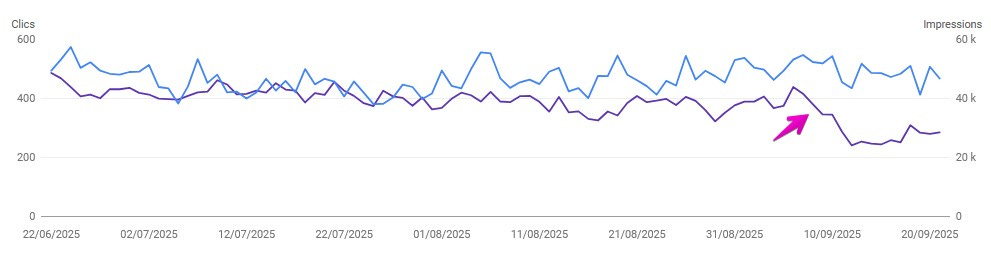
Pour interpréter bien cette baisse, revenons au début de l’article et rappelons d’où venaient ces impressions : il s’agissait majoritairement des bots qui envoyaient en masse les requêtes à Google en récupérant à chaque fois TOP-100 résultats.
Ainsi, si votre site apparaissait en position 55 sur une requête, il enregistrait une impression.
Un argument en faveur de l’idée que ces impressions ont été artificiellement gonflées par les outils de collecte automatisés est que le volume de clics, lui, est resté inchangé.
C’est dans ces moments-là qu’on réalise l’ampleur du bruit présent dans les données de la Search Console. Maintenant on en a un peu moins.
2. La longue traîne amputée
Un autre phénomène que nous pouvons constater est la réduction notable du nombre de requêtes apparaissant au-delà de la première page (TOP-10) des résultats de recherche.
Voici un extrait d’un dashboard Looker Studio d’un client.
Le graphique récupère les données depuis Google Search Console, et compte le nombre de requêtes positionnées en 1ère page de Google et au-delà de la 2ème :
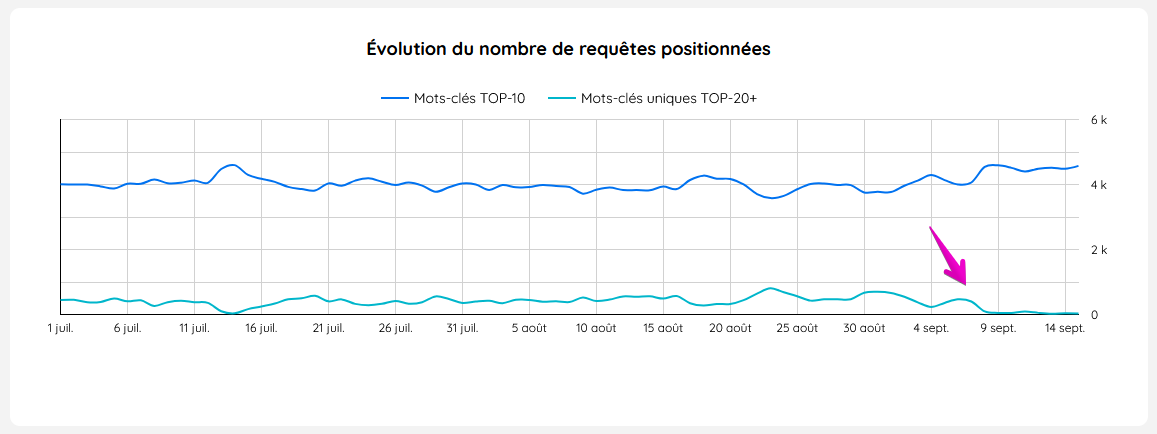
Depuis le 10 septembre, il n’y a quasiment aucune requête.
J’ai vu passer sur les réseaux sociaux et dans plusieurs publications des mécontentements par rapport au fait que Google ait réduit la longue traîne des requêtes, ce qui nous prive désormais de nombreux mots-clés potentiellement pertinents et utiles.
Mais souvenons-nous de ce que nous évoquions en introduction : ces requêtes étaient avant tout visibles par des systèmes automatisés de scraping des résultats Google.
Autrement dit, ce que nous perdons ici correspond surtout à des phrases de recherche artificiellement générées et gonflées par les machines.

Suivi de positionnements : Outils de monitoring en difficulté
Mais ceux qui ont le plus souffert de cette mise à jour de Google, ce sont les services de scraping des résultats de recherche de Google .
On y trouve un large éventail de plateformes :
Les services de suivi de positions (comme Seranking, Accuranker, STAT),
Les outils d’analyse SEO (Semrush, Sistrix, SearchMetrics, Ahrefs),
Les plateformes de SERP API, qui collectent les résultats de recherche pour ensuite revendre ces données (Data For SEO, ValueSERP, SERP API, BrightData).
Tous ces services collectaient par défaut le TOP 100 des résultats, ce qui ne nécessitait qu’une seule requête envoyée au moteur de recherche.
Désormais, ils n’obtiennent que 10 résultats par requête.
Pour continuer à récupérer le TOP 100, il faut donc effectuer 9 requêtes supplémentaires.
Comme on peut l’imaginer, cela augmente considérablement le temps de collecte, les ressources nécessaires et, bien sûr, les coûts.
Certains outils ont déjà recalculé leurs tarifs, par exemple pour récupérer TOP-100 résultats sur une requête :
DataForSEO demande désormais $0.00465 au lieu de $0.0006 (x7.75)
ValueSERP - consomme désormais 10 crédits au lieu d’1 seul.
Seranking, notre principal outil de suivi de positionnements dans l’agence (iProspect) dans lequel on suit environ 2 millions de mots-clés, affiche depuis 3 semaines un message d’alerte que les relevés des positions éprouvent des ralentissements :
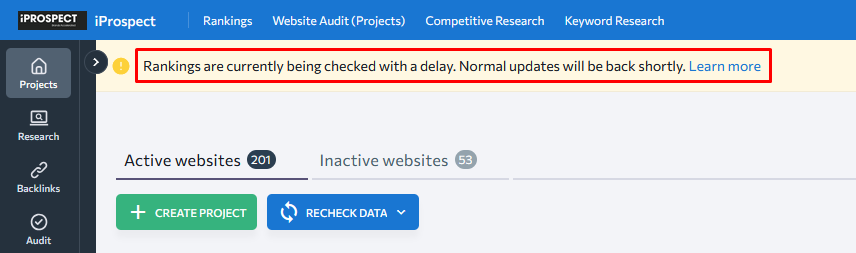
Si pendant la 1ère semaine depuis l’abandon de &num=100, on voyait l’outil bien ralenti, les derniers jours, ils ont réussi à récupérer la vitesse du relevé des positions d’auparavant.
A quoi ça sert de suivre les mots-clés en positions 50, 60, 70 ?
On peut se poser une très bonne question :
- Après tout, qu’importe si nous ne voyons plus les positions 50, 60, 70, etc. De toute façon, les utilisateurs ne les consultent pas et elles ne génèrent pas de clics.
Mais la visibilité élargie au-delà du TOP-10 nous apportait beaucoup d’autres informations utiles en nous permettant de :
Identifier des opportunités de mots-clés à exploiter à court terme (mots-clés en 2ème - 3ème page).
Repérer des pages intéressantes à mettre à jour ou à améliorer.
Détecter la cannibalisation de pages (lorsque plusieurs pages sont optimisées pour la même requête).
Suivre la progression de nouveaux contenus, aussi bien les siens que ceux des concurrents.
Suivre l’efficacité des backlinks acquis (plus claire quand on a une vision élargie des positionnements).
etc. etc.

GEO
Tout est interconnecté dans notre microcosme de la recherche. Et un changement dans une partie provoque des secousses dans une autre.
Il y a environ 3 mois, j’écrivais que ChatGPT avait délaissé Bing au profit de Google.
À ce moment-là, selon mes observations, pour établir la liste des pages citées, SearchGPT utilisait environ les 20 premiers résultats de recherche Google (avec un taux de correspondance de 70 à 90 %).
Aujourd’hui, lorsque je compare les pages citées par ChatGPT, elles coïncident beaucoup avec les pages issues du TOP-10 de Google (sur la base de mon échantillon de ~500 prompts analysés avec 1 et 2 requêtes fan-out que je monitore avec LLM Insights).
Le fan-out désigne le procédé par lequel votre prompt est décomposée en une ou plusieurs sous-requêtes parallèles, envoyées dans un ou des moteurs de recherche externes, dont les résultats sont ensuite agrégés pour produire une réponse plus complète.
Voici 3 exemples, mais vous pouvez le vérifier également très facilement de votre côté :
Il est certain que SERP API exploité par OpenAI a été confrontée aux mêmes contraintes que les autres services et se limite désormais aux dix premiers résultats.
On le remarque aussi à travers une baisse sensible de la diversité des sources citées dans ChatGPT, qu’il s’agisse des pages ou des domaines.:
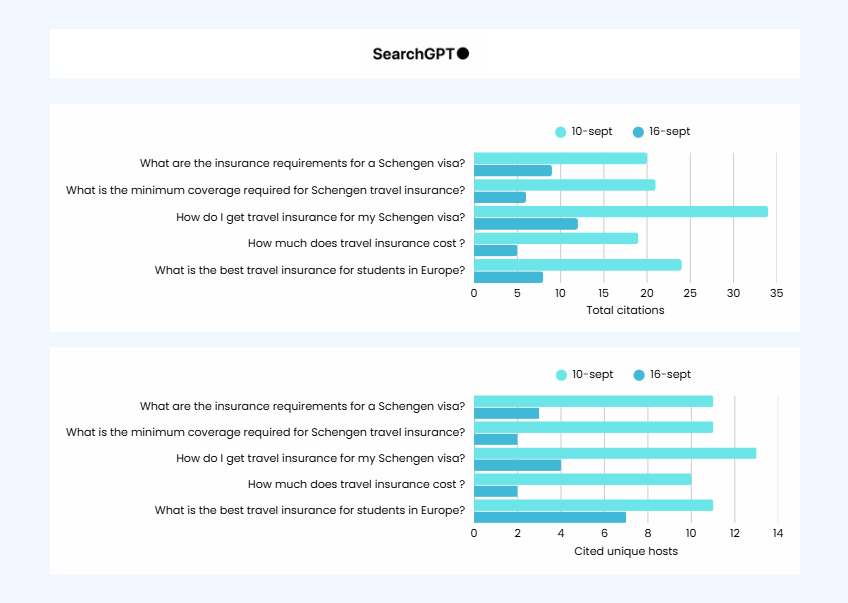
Si on prend un peu de hauteur et regarde cet aspect sur un échantillon plus large de prompts, on constate qu’effectivement le nombre de sources (pages) externes utilisées par SearchGPT a drastiquement baissé depuis le 10 septembre.
Il ne s’agit pas d’un nombre de citations dans les réponses, mais de la diversité des sources utilisées :
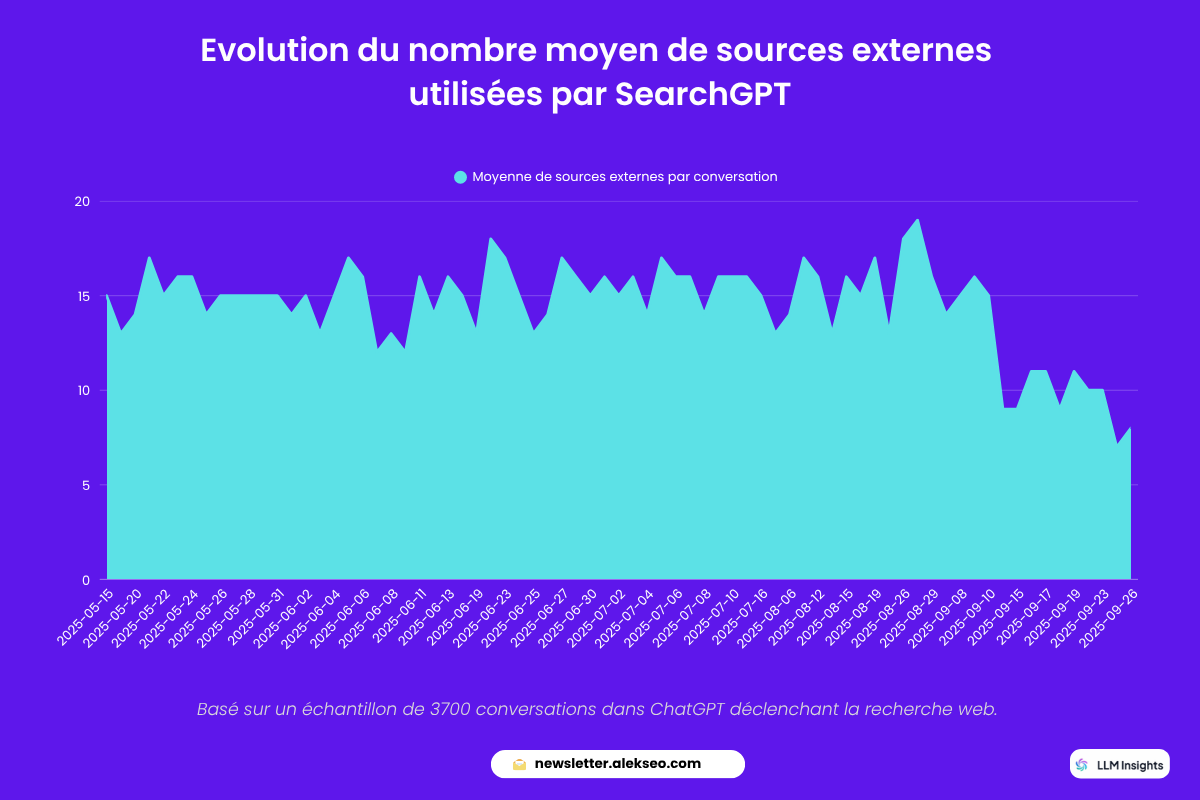
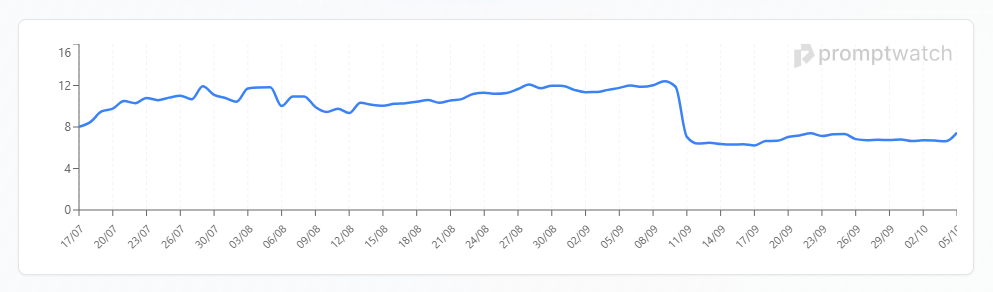
La même tendance est confirmée par un autre outil du marché PromptWatch :
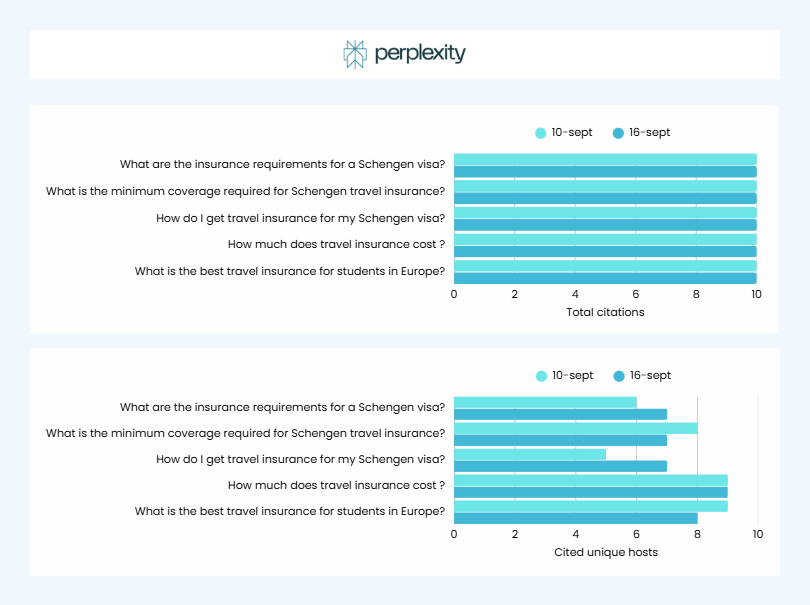
En même temps, ce qui est intéressant : les citations de Perplexity AI sont restées presque sans changements. La plateforme paraît beaucoup moins dépendante de Google que ne l’est SearchGPT :
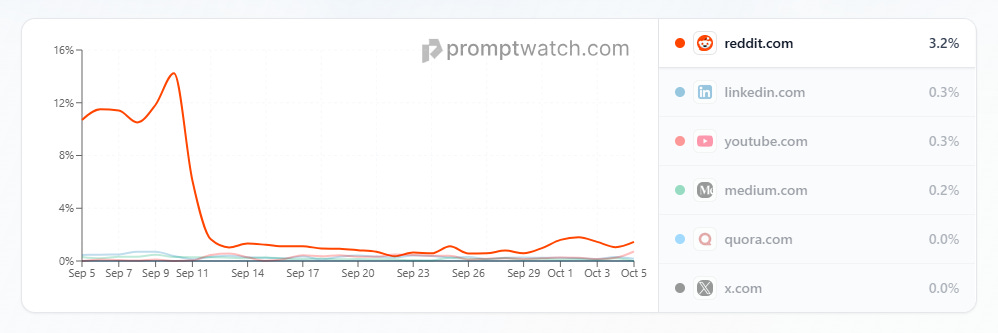
La disparition des résultats profonds de Google a également secoué la présence de certains sites qu’on avait l’habitude de voir dans les réponses de SearchGPT, en l’occurrence Reddit dont la présence a chuté de 14% à 3% :
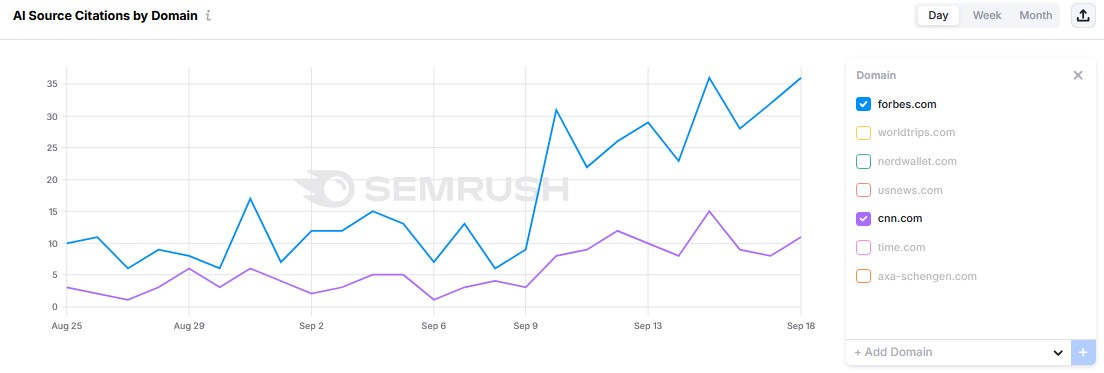
Une autre conséquence: moins il y a de diversité de sources, plus de poids obtiennent des sources bien positionnées, les services de Google et les sources partenaires de OpenAI.
Des médias comme Forbes, CNN ou YouTube connaissent un regain de visibilité depuis le 10 septembre :
Et la dernière chose à propos de GEO.
OpenAI a besoin de données fraîches et à jour, mais il est difficile de considérer le passage par des intermédiaires comme SERP API comme une stratégie viable à long terme. Google continuera à lutter contre la collecte automatique de ses données poussant OpenAI à chercher d’autres solutions.
Cette situation pourrait amener OpenAI à changer une nouvelle fois de moteur de recherche partenaire — à l’image de Claude AI, qui s’appuie sur Brave — ou à développer son propre moteur doté d’un index indépendant, à la manière de Perplexity. Un sacré enjeu !

Voilà, c’est tout pour aujourd’hui, à très bientôt!