
#12. Google & la règle des 130 jours
Découvrez comment Google gère son indexation avec la règle des 130 jours.

Salut, c’est Alexis 👋
Bienvenue à 36 nouveaux abonnés depuis la dernière édition ! Si vous n’êtes pas encore abonné, il n’y a rien de plus simple ⬇️
Et si le contenu vous plaît, n’hésitez pas à le partager à vos amis! 😉

Cet article contient beaucoup de visuels, si vous avez des difficultés pour le visualiser, voici le lien vers la version Web complète : https://newsletter.alekseo.com/p/12-google-and-la-regle-des-130-jours


L’algorithme de classement de Google repose sur un certain nombre de valeurs intrinsèques définies manuellement par les ingénieurs.
Autrement dit, ce sont des paramètres fixes, qui ne varient pas dynamiquement et s’appliquent comme des règles absolues.
Dans cette édition de la newsletter, j’aimerais vous parler de l’une de ces valeurs, qui permet de mieux comprendre comment le principal moteur de recherche gère un élément fondamental de son algorithme de classement : l’indexation.
Être indexé par Google et y rester constitue un enjeu stratégique pour tout site web.
En effet, si ses pages ne sont pas indexées, tous les autres efforts — création de contenu, acquisition de liens, optimisation de la conversion, et bien d’autres — deviennent inutiles.
Or, l’index de Google n’est pas illimité, ou plutôt, Google ne souhaite pas qu’il le soit.
En 2020 la taille de l’index de Google s’élevait à 400 milliards de documents (pages). Ce chiffre a été révélé lors du contre-interrogatoire de Pandu Nayak, vice-président de la recherche chez Google, dans le cadre du procès antitrust USA contre Google.
Car un plus grand nombre de pages indexées implique davantage d’espace de stockage, plus de puissance de calcul pour les analyser, les classifier et les surveiller.
Cela entraîne donc des coûts opérationnels accrus, que toutes les entreprises cherchent aujourd’hui à réduire.
Ainsi, le moteur de recherche de Google déploie tout un arsenal de techniques pour contrôler la croissance de son index : canonicalisation (déduplication), crawl prédictif, pénalités, sanctions, et bien d’autres encore.
Mais qu’en est-il des pages déjà présentes dans l’index depuis longtemps ? Probablement, elles ne méritent pas toutes d’y rester.
Google dispose d’un mécanisme bien précis pour effectuer ce ménage.
Je vous propose que nous menions ensemble notre propre enquête pour le découvrir !

Préparons notre terrain de jeu
Nous allons utiliser dans nos recherches Screaming Frog SEO Spider, dont la version payante permet d’enrichir nos données de crawl des données issues de l’API de Google Search Console :
Choisissez dans le menu : Configuration > Accès à l’API > Google Search Console.
Connectez-vous à votre compte.
Passez à l’onglet “Inspection d’URL”.
Cochez les 2 cases comme sur l’image ci-dessous:
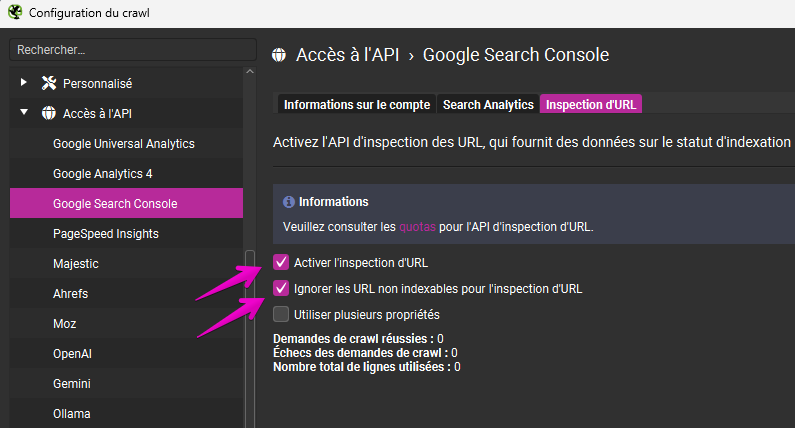
"Inspection d’URL" est une API intégrée à l’API de Google Search Console, qui permet de récupérer des informations sur l’état technique des pages telles qu’elles sont connues par le moteur de recherche.
L’outil est très pratique pour ne pas faire inspecter les urls qui vous intéressent une par une dans l’interface de la Search Console. La seule limite est 2000 pages par jour par propriété (qu’on peut contourner avec la création de plusieurs propriétés).
Il est temps de lancer votre crawl.
Le crawl lancé, ouvrez l’onglet “Google Search Console” où vous verrez plein d’informations utiles issues directement de l’index de Google :
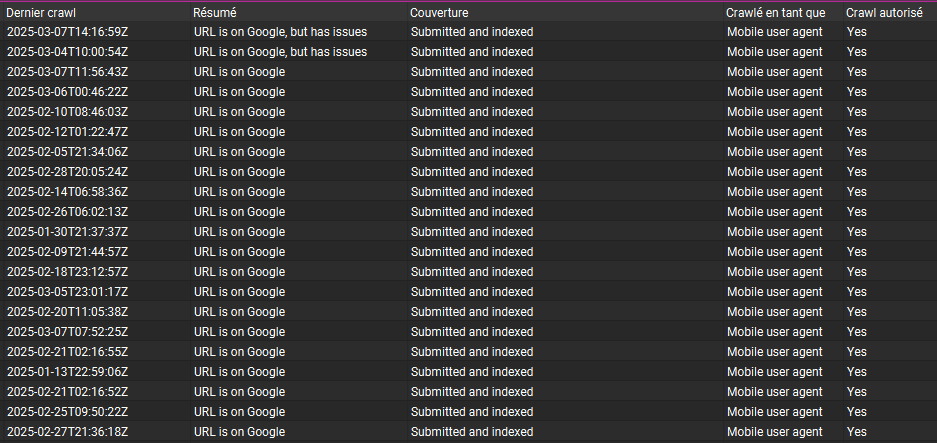
On se retrouve devant 20 colonnes d’indicateurs techniques en vrac et pour l’instant rien ne semble être clair.
Mais comme disait Henri Bergson il y a 90 ans : Le désordre est simplement l’ordre que nous ne cherchons pas 🙂
Réduisons notre périmètre d’étude à 4 colonnes :
Résumé (page présente dans l’index de Google ou pas)
Couverture (raison pour laquelle la page n’est pas indexé, si c’est le cas).
Dernier crawl (date de la dernière exploration de la page par Googlebot)
Nombre de jours depuis le dernier crawl.
Là, nous découvrons en face de chaque url si elle est indexée par Google ou pas et le temps passé depuis la dernière exploration.
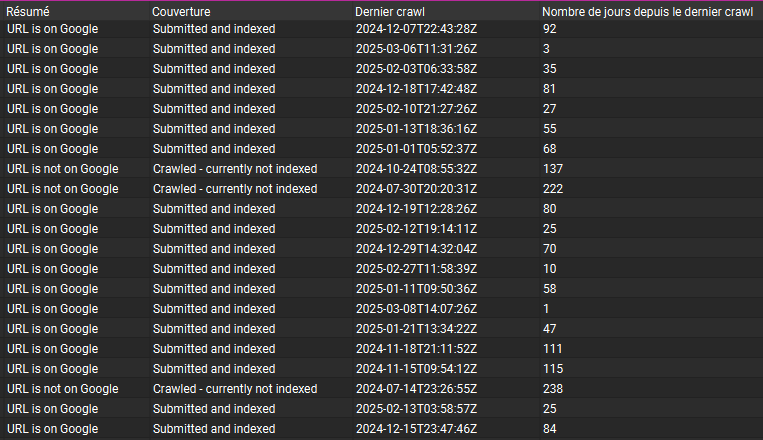
Trions les données par la colonne "Nombre de jours depuis le dernier crawl" dans l'ordre croissant.
Et soudain, nos données s’organisent en un système clair de causes et conséquences.
Investiguons-le sur 5 exemples ⬇️
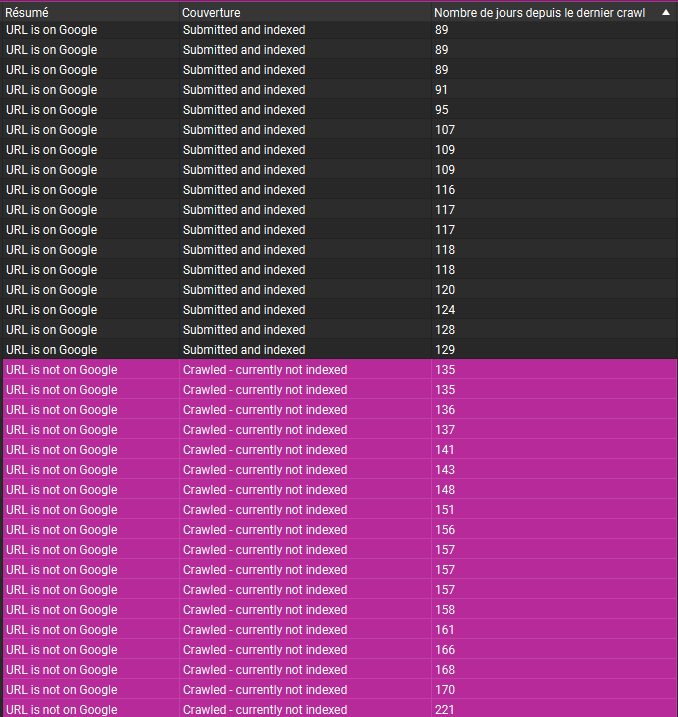
Cas 1 : Site officiel d’un fabricant de pneus
Ceci est un des fabricants les plus connus des pneus sur le marché portugais.
En faisant toutes les traitements décrites ci-dessus, on découvre 2 états des pages dans la colonne “Résumé” : “URL is on Google“ et “URL is not on Google”.
Mais le plus intéressant se passe si on regarde la colonne “Nombre de jours depuis le dernier crawl”.
Il semble qu’il y ait un rapport de causalité entre la fréquence d’exploration et l’état d’indexation d’une URL.
Plus précisément, les URLs semblent se faire désindexer, si Googlebot ne les a pas explorées depuis 130 jours :
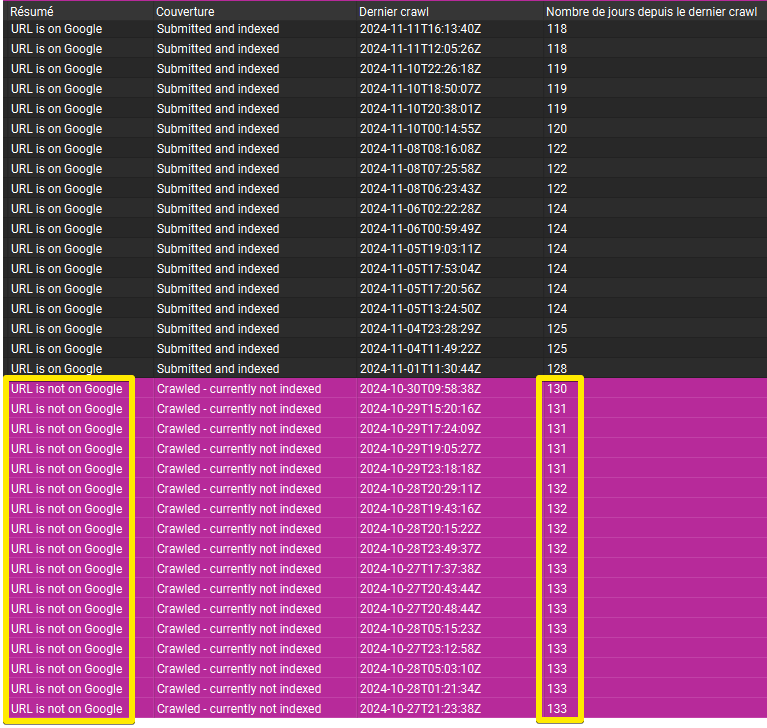
Une précision importante : au moment de la configuration de Screaming Frog nous avons coché la case pour n’envoyer dans l’inspecteur d’URLs que les URLs indexables.
Autrement dit, dans nos données analysées il n’y a que les pages techniquement correctes (pas de noindex, ni rel canonical, ni bloquées dans robots.txt ou autre).Pour éviter le biais du survivant voici 4 autres exemples réels.
Cas 2 : Site média (sport)
Ceci est un site d’un autre type, mais sur lequel on observe la même tendance:
Les pages qui n'ont pas été explorées depuis 130 jours sont automatiquement retirées de l'index de Google.
Elles passent du statut "Submitted and indexed" à "Crawled - currently not indexed" :
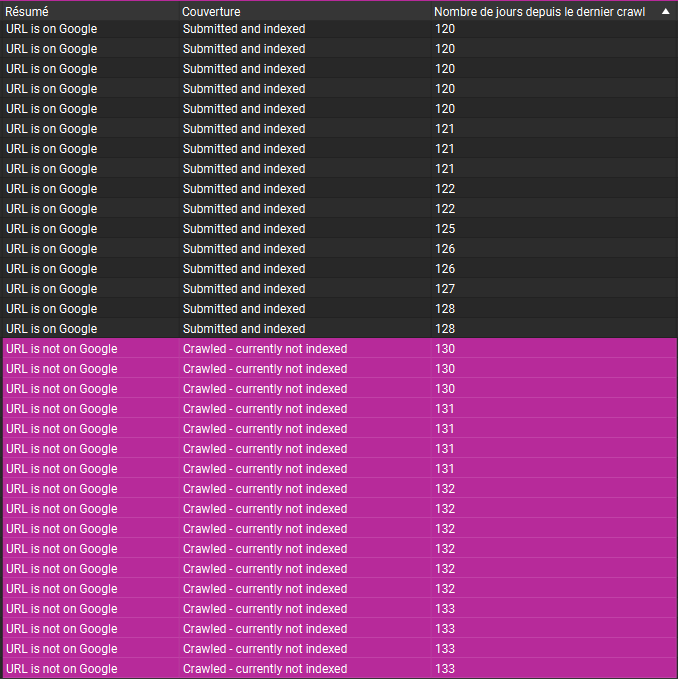
Cas 3 : Magazine de mode
Exactement la même tendance sur ce magazine français de mode :
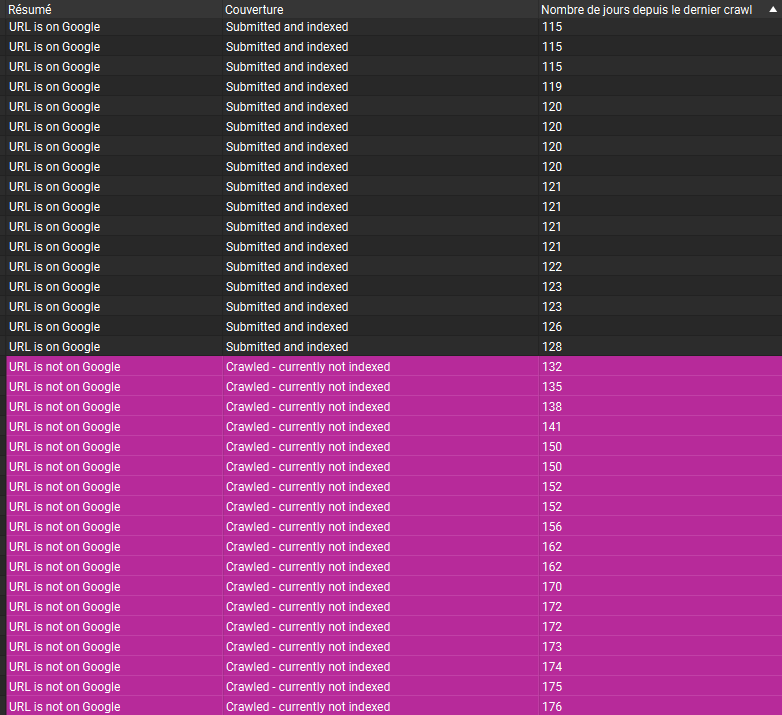
Cas 4 : Site corporate avec un forum
Encore un autre type de site : business avec un forum intégré pour gérer la partie questions-réponses - le même constat, le seuil de 130 jours :
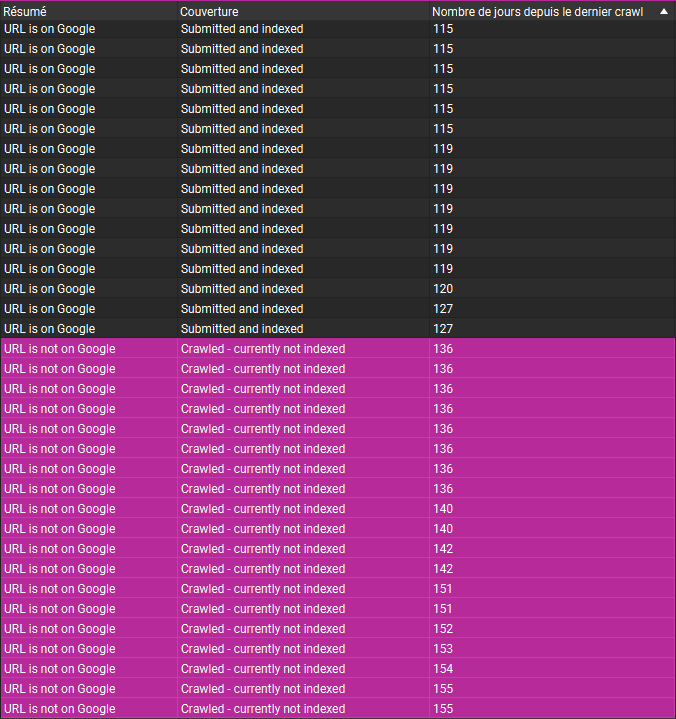
Cas 5 : Site institutionnel
Et le 5ème et le dernier exemple, un site institutionnel français - pareil :

La règle des 130 jours
Dans tous ces exemples observés, nous constatons toujours la même tendance :
L’état d’indexation de nos pages dépend de la fréquence d’exploration par Google.
Google semble appliquer un seuil d’exploration statique de 130 jours. Chaque page du site à sa propre fréquence d’exploration qui évolue dans le temps. Si celle-ci dégrade au point que Googlebot n’a pas exploré la page pendant 130 jours, cette dernière est retirée de l'index.
Il y a tout un intérêt d’analyser ses pages avec une fenêtre d’exploration de 130 jours et plus pour les optimiser et valoriser davantage.

Que faire avec les pages non explorées depuis 130 jours ?
Maintenant, la question légitime : qu’est-ce qu’on fait avec cette connaissance ?
Pour cela, il faut rappeler comment le moteur de recherche alloue et répartit ses ressources d’exploration.
La fréquence d’exploration est une valeur dynamique que le moteur cherche constamment à optimiser pour crawler au mieux les pages qui en valent le coup.
Si vous voulez augmenter notre fréquence d'exploration, vous devez d'une manière ou d'une autre convaincre le moteur de recherche que votre contenu mérite d'être récupéré, car c'est essentiellement ce à quoi le planificateur prête attention.
La fréquence d’exploration est calculée principalement en se basant sur 2 groupes de critères :
Qualité du contenu de la page.
Pagerank de la page.
Maintenant récupérez vos pages non explorées depuis 130 jours et essayez de répondre aux questions suivantes.
Du point de vue qualitatif :
Ces pages, qu’est-ce qu’elles ont en commun ?
Appartiennent-elles à un type particulier?
Par exemple, sur notre site de fabricant de pneus (cas 1), parmi les pages en question on retrouve celles de catégories par marques sans produits, ni contenu de différenciation.
Sur le site média (cas 2) : il s’agit des pages de tags très similaires, qui peuvent être optimisées et enrichies davantage.
Sur le magazine de mode (cas 3) il s’agit des contenus très courts conçus initialement pour être diffusées dans les réseaux sociaux.
Améliorer la qualité des pages, permet d’améliorer leur exploration et ainsi l’indexation :
La planification est très dynamique. Dès que nous recevons des signaux de l’indexation indiquant que la qualité du contenu s’est améliorée sur un certain nombre d’URL, nous augmentons simplement la demande.
Gary Illyes, Google Analyst.
Du point de vue du Pagerank :
A côté du contenu, la fréquence d’exploration d’une page par Google est très étroitement liée à l’autorité de celle-ci, formalisée dans la notion du Pagerank.
Plus une page s’enfonce dans les profondeurs d’un site, moins elle est considérée comme importante.
Et lorsque cette importance atteint un seuil minimal, au point que Googlebot ne juge pas nécessaire de la crawler plus d’une fois tous les 130 jours, elle finit par sortir de l’index.
Il s’agit en quelque sorte d’un nettoyage effectué par Google, qui supprime de l’index les pages jugées peu importantes. Cela explique également pourquoi certaines pages qui étaient depuis longtemps indexées à un moment données peuvent en être exclues.
Questions à se poser sur cet aspect :
Où se trouvent les pages désindexées dans l’arborescence ?
Quel est leur niveau de profondeur ?
Reçoivent-elles suffisamment de liens internes comme externes ?
2 derniers conseils :
Si vous voulez savoir quelles sont les meilleures pages de votre site aux yeux de Google, la fréquence d’exploration est l’un des indicateurs les plus fiables.
Pour réaliser cette étude sur l’ensemble de votre site, vous pouvez passer par l’analyse de logs. Demandez à votre hébergeur ou développeur d’exporter les logs pour au moins 130 derniers jours. Croisez-les avec vos données de crawl: les pages crawlées qui ne sont pas présentes dans les fichiers de logs sur 130 derniers jours ne sont certainement pas indexées.

Merci d’avoir lu jusqu’à la fin, j’espère vous avez trouvé des choses utiles!
c’est tout pour aujourd’hui, à très vite !
Merci, hyper intéressant
Excellent article Alexis, merci pour ton analyse :-)